「A案件のレビューを終えてからB案件に戻ったら、Claude Codeとのやり取りも、頭の中の文脈も、全部リセットされていた」。受託の現場で1人が複数案件を抱えるとき、この“切替コスト”が一日の生産性をそのまま削っていきます。
ブランチを切り替えるたびに作業ディレクトリの状態が変わり、エディタも、ターミナルも、Claude Codeのセッションも、いったん閉じて立ち上げ直す。気づけば1日1案件しか前に進んでいない、というPMやテックリードは少なくありません。
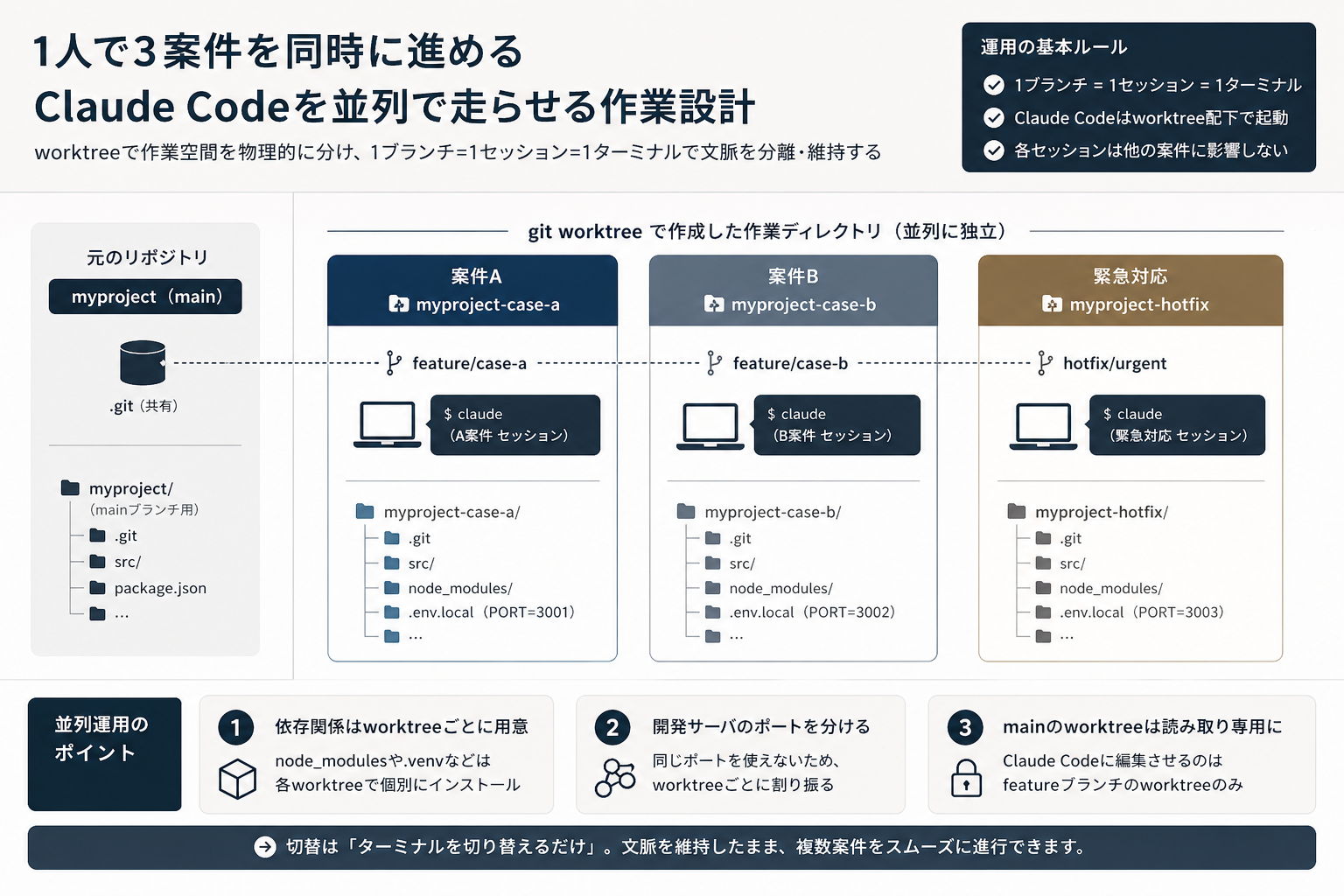
この記事では、その問題を「セッション設計」ではなく「ディレクトリ設計」で解く方法、つまり git worktreeで案件ごとに作業空間を物理的に分け、Claude Codeを案件単位で並列に走らせる運用 を整理します。1ブランチ=1セッション=1ターミナルとして固定するための、コマンドと運用ルールまでまとめます。
なぜ「セッションを増やす」では解決しないのか
Claude Codeを複数立ち上げるだけなら、ターミナルを2枚開けば済みます。ただし同じリポジトリの同じディレクトリを共有していると、片方で git checkout した瞬間に、もう片方のセッションが見ているファイルも書き換わります。
結果として起きるのは次のような事故です。
- A案件で編集中のファイルが、B案件のブランチに切り替えた瞬間に消える
- Claude Codeが直前まで読んでいたファイルパスの中身が変わり、前提が崩れる
- ビルド結果や
node_modulesがブランチ間で混ざり、原因不明のエラーが出る
つまり問題は「セッション数」ではなく「作業ディレクトリが1つしかないこと」です。文脈を分けたければ、ディレクトリごと分けるのが最短ルートになります。
git worktreeで作業空間を物理的に分ける
git worktree は、1つのリポジトリから 複数の作業ディレクトリ を生やす仕組みです。ブランチごとに独立したフォルダが用意されるため、切替コストがゼロになります。
最初のセットアップは以下のような構成にします。
~/work/
myproject/ # 元のクローン(mainブランチ用)
myproject-feature-a/ # A案件用 worktree
myproject-feature-b/ # B案件用 worktree
myproject-hotfix/ # 緊急対応用 worktreeコマンドはシンプルです。
# A案件用のworktreeを作る
cd ~/work/myproject
git worktree add ../myproject-feature-a feature/case-a
# B案件用も追加
git worktree add ../myproject-feature-b feature/case-b
# 一覧確認
git worktree listそれぞれのディレクトリで git status を打つと、別々のブランチに切り替わっていることが分かります。1つのディレクトリで checkout を繰り返す必要がなくなる ので、エディタもターミナルもClaude Codeも、案件ごとに開きっぱなしにできます。
不要になったらディレクトリを消した上で、
git worktree remove ../myproject-feature-aで片付けます。これで履歴やリモート設定は元のリポジトリ側に残り、worktreeだけが消えます。
1ブランチ=1セッション=1ターミナルに固定する
worktreeを作っただけでは、運用はぶれます。並列で走らせるなら 「1ブランチ=1セッション=1ターミナル」をルール化する のが現実解です。
具体的には次のように対応関係を固定します。
- ターミナル1:
~/work/myproject-feature-aにcdしてからclaudeを起動(A案件用) - ターミナル2:
~/work/myproject-feature-bにcdしてからclaudeを起動(B案件用) - ターミナル3:
~/work/myproject-hotfixにcdしてからclaudeを起動(緊急対応用)
ポイントは、Claude Codeを 必ずそのworktreeディレクトリをカレントにして起動する ことです。各セッションがそのworktree配下のファイルしか見ない状態になるため、案件AのClaude Codeに案件Bのコードが混ざる事故が物理的に起きません。VS Codeなら、worktreeごとに別ウィンドウで開いておけば、エディタ側の文脈も自然に分離されます。
切替の作業は「Claude Codeに状況を再度説明する」ではなく「ターミナルを切り替える」だけです。これこそが、工数削減の肝となる部分です。
並列運用で詰まりがちな3つのポイント
実際にやってみると、いくつか引っかかりやすい場所があります。ここでは、特につまずきやすいポイントを3つ紹介します。
1. 依存関係(node_modulesなど)はworktreeごとに必要
worktreeは .git だけを共有しています。node_modules や .venv といった依存関係は 各worktreeで個別にインストール する必要があります。最初の npm install を忘れると、Claude Codeが「依存が見つからない」と言い出してハマります。
2. 同じポート番号で開発サーバを起動できない
A案件もB案件も localhost:3000 を奪い合うと、片方しか起動できません。worktreeごとに ポート番号を割り振っておく のが楽です。.env.local にポートを書き分けるか、PORT=3001 npm run dev のように起動コマンド側で指定しておきます。
3. メインブランチのworktreeをClaude Codeに直接触らせない
main のworktreeは、レビューや結合確認など 読み取り中心の作業専用 にします。Claude Codeに編集させるのは必ず feature ブランチのworktreeに限定する、というルールを敷くと、main を汚す事故が起きません。これは PMがClaude Codeを使うときの3ルール の「最終判断はPMが握る」という考え方と相性が良い設計です。
そのまま使える運用テンプレート
新規案件をスタートするときの初動を、テンプレ化しておきます。
# 1. 案件用ブランチを作ってworktreeを切る
cd ~/work/myproject
git worktree add ../myproject-${CASE} feature/${CASE}
# 2. worktreeに移動して依存関係を入れる
cd ../myproject-${CASE}
npm install
# 3. Claude Codeをこのworktreeディレクトリで起動
claude${CASE} には案件略称(case-a など)を入れます。特に重要なのが手順3です。必ずworktreeをカレントディレクトリにした状態でClaude Codeを起動してください。これで案件1件=ターミナル1枚が維持でき、案件が3つに増えても、頭の中の切替は 「タブを切り替える」 だけになります。
Claude Codeへの最初の依頼文も、案件ごとにテンプレ化しておくと立ち上がりが速くなります。書き方の指針は Claude Codeへの依頼を4要素で書く で詳しく整理しているので、worktreeの初期化と合わせて使うと効果が大きいはずです。
まとめ:稼働密度はディレクトリ設計で上げる
「複数案件を1人で回せない」のは、能力やマルチタスクの問題ではなく、作業空間が1つしかないこと が大きな原因です。git worktreeで案件ごとにディレクトリを切り、1ブランチ=1セッション=1ターミナルでClaude Codeを並列に走らせるだけで、切替コストの大半は消えます。
組織として並列運用を当たり前にしていくフェーズでは、個人のテクニックに留めず、チームの標準作業として定着させる必要があります。チーム全体での導入ステップは Claude Codeが社内で使われない3つの原因と定着フレーム を参考にしてください。
worktreeとClaude Codeの並列運用を、属人技ではなく 再現できる開発体制 に組み込みたい方は、テックエイドのAI開発活用シリーズ(AIX-101 / AIX-102)がお役に立てるはずです。自律的に機能するAI開発体制を、現場の作業フローまで落とし込みたいPM・テックリードに向けた構成です。